18、散列表(上)
思考:Word 文档中的单词拼写检查功能是如何实现的?
主要内容
定义
散列表的英文叫“Hash Table”,我们平时也叫它“哈希表”或者“Hash 表”。
散列表是基于数组的随机访问特性,本质是数组的一种扩展。
举例说明:
假设有 100 人参加运动会,参赛编号为:年级+班级+号码(1 到 100),比如 05(5 年级)03(3 班)06(号码),那如何实现通过参赛编号快速找到选手信息?
可以用数组存选手信息,参赛编号截取出后两位的【号码】,就【号码】为 1 的放入数组下标为 1 中,那参赛编号中【号码】为 k 的放入数组下标为 k 中。
这样就直接通过参赛编号的【号码】,对应取数组下标得到选手信息,并且时间复杂度为 O(1),很高效。
上述的关键信息有:【号码】我们叫做键(key),将【号码】转为数组下标的过程称为散列函数(hash 函数),将散列函数计算出的值叫做散列值(hash 值)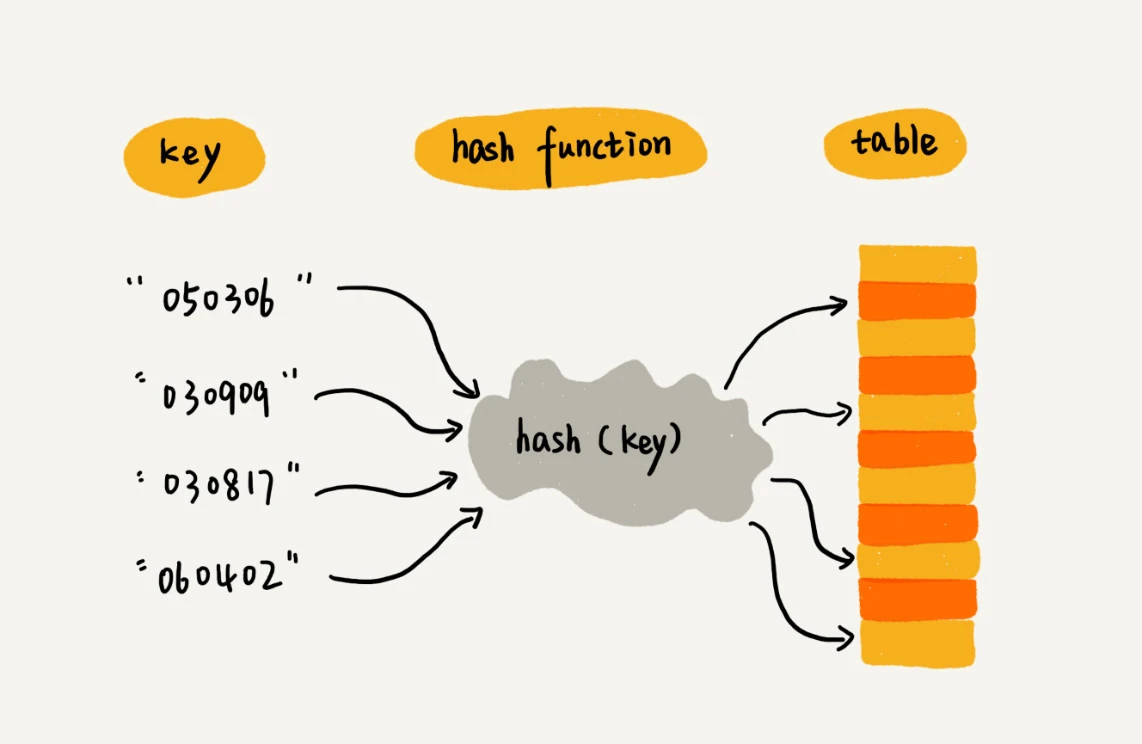
总结:散列表就是将某个值通过散列函数转为数组下标,然后再将数据存储到数组对应下标中。这样取值时,就可通过散列函数将某个值转为数组下标,直接去数组[下标]对应数据
散列函数
作用就是将传入的值转为数组下标
上述运动会例子中的散列函数如下:
1 | |
设计散列函数的要点:
- 返回值要为非负整数
- 相同 key,返回值必相同,即:key1 = key2,hash(key1) = hash(key2)
- 不同 key,返回值必不同,即:key1 ≠ key2,hash(key1) ≠ hash(key2)
第 1、2 两点很好理解
第 3 点,看起来很合理,但实际中很难避免,很可能出现不同 key,返回相同的值,即散列冲突
比如正常的 hash 生成,都可能出现不同 key 生成相同的 hash 值,这也就是 hash 冲突。
基于抽屉原理:当输入空间大小远大于输出空间时,不同的输入产生相同输出的情况不可避免。
那如何解决散列冲突呢?
开放寻址法
核心思想:如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。那如何重新探测新的位置呢?
探测法之线性探测
核心思想:生成的散列值,对应的数组内有值后,则往后找空的然后存入,若找到尾部都没空,则从头开始找,找到空的存入,否则存入失败。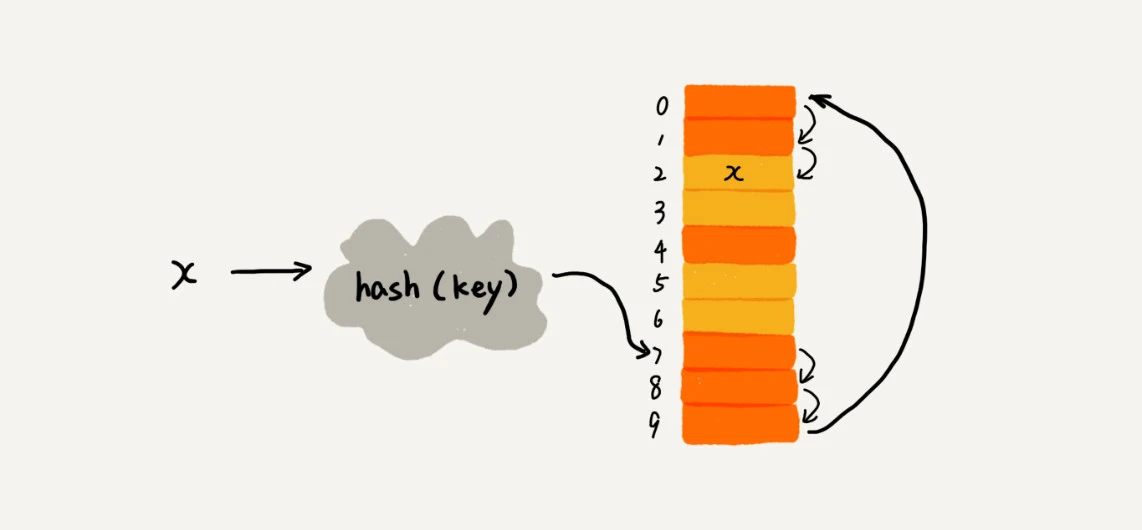
橙色代表有值,黄色代表无值
数据为 x,生成的散列值为 7,但发现数组[7]有值了,则往后找,发现都有值,则从头找,找到了数组[2]无值,则存入 x。
取值时,生成的散列值为 7,取数组[7]的值跟 x 对比下,一致则返回,不一致则往后找分别取值与 x 对比,到尾部了还未找到,则从头找,找到了数组[2]的值等于 x,最终返回 x,如果遍历到空值了还未找到,则说明不在数组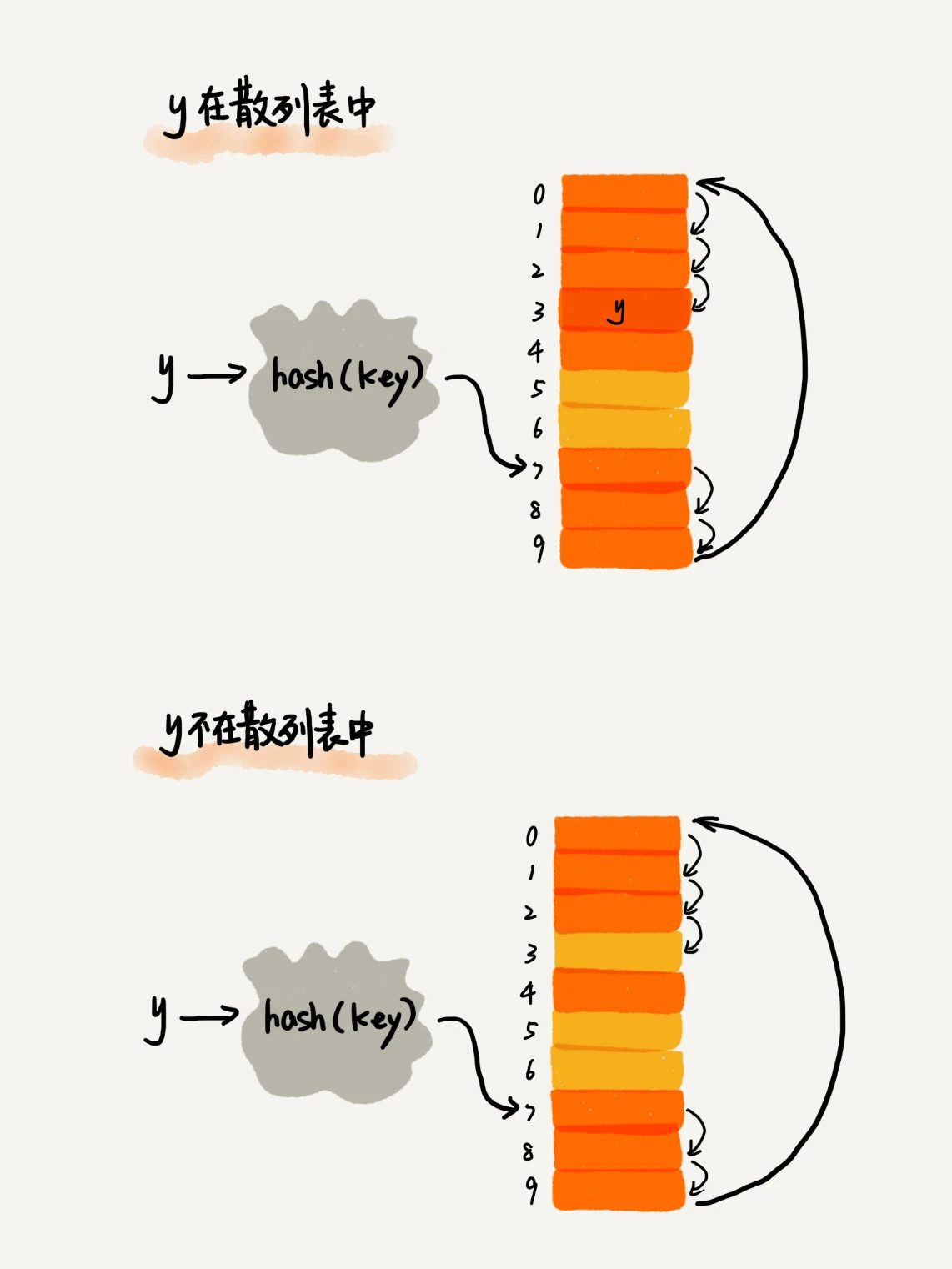
缺点:数据越多,探测耗时越长,最坏为 O(n)
探测法之二次探测
类似于线性探测,只是探测颗粒度改为二次方:hash(key)+0、hash(key)+1^2、、hash(key)+2^2……
探测法之双重散列
使用一组散列函数:hash1(key)、hash2(key)、hash3(key)……
当 hash1(key) 出现冲突后,再使用 hash2(key),依次直到找到不冲突的散列值
散列表的空位,一般用装载因子表示,计算方式为:已填入数据 / 散列表长度
装载因子越大,则空位越少,散列冲突就会越多
链表法
更常用的方法。
将产生冲突的散列表值更改为链表形式(桶或槽),然后依次存入散列值相同的元素值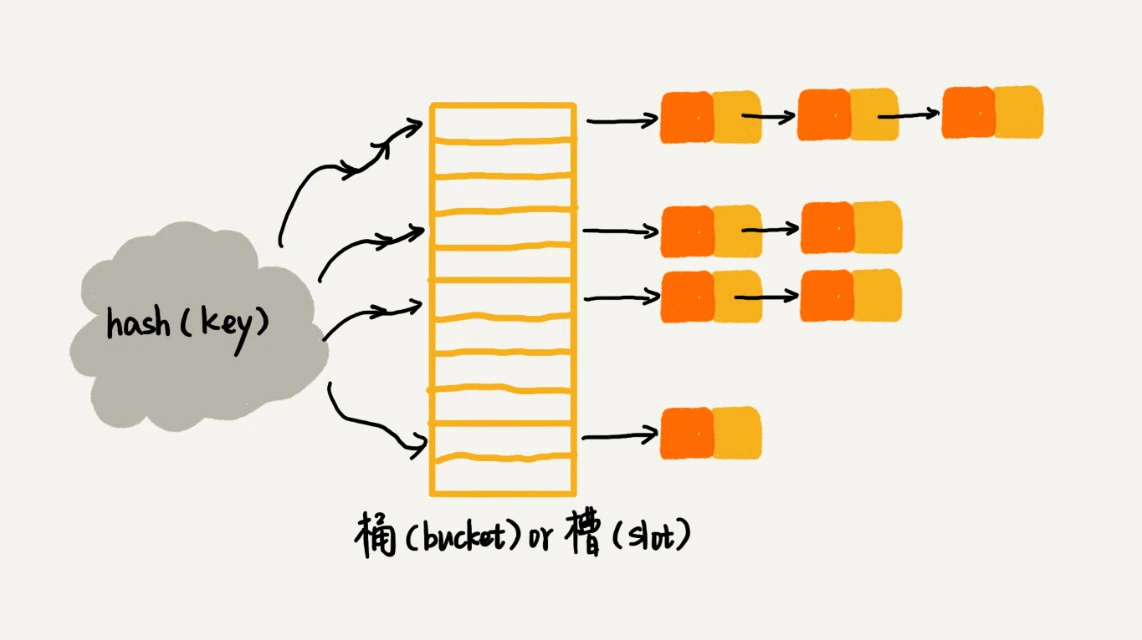
取值时,则遍历链表找到对应的值
解答思考
思考:Word 文档中的单词拼写检查功能是如何实现的?
解答:将所有单词经过散列函数存入散列表中,然后用户输入的单词也经过散列函数生成散列值,去散列表[散列值]取值,如果没取到则单词可能有误,否则单词正确。
这种算法,取值时间复杂度为 O(1),十分高效。
内容总结
散列表白话:基于数组结构,将要存入的值经过转换生成唯一的非负整数,把非负整数作为数组下标,然后将数据存入到数组中。
散列表官方:基于数组结构,将 key 经过散列函数转为散列值,把散列值作为数组下标,然后将数据存入到数组中。
核心思想:生成一个与数组下标一一对应的值
散列冲突:不同 key 生成的散列值一样了,导致冲突
解决散列冲突:开放寻址法:找有空的然后存入、链表法:将冲突的转为链表然后存入
新的思考
假设我们有 10 万条 URL 访问日志,如何按照访问次数给 URL 排序?
1、先遍历十万条 URL,通过散列函数将 URL 转为散列值,将访问次数存入数组[散列值]中,本次操作时间复杂度为 O(n)
2、若最大访问次数较小,则再使用桶排序来排序该散列表;若访问次数很大(>10W),则使用快速排序来排序该散列表
有两个字符串数组,每个数组大约有 10 万条字符串,如何快速找出两个数组中相同的字符串?
1、遍历第一个字符串数组,将字符串作为 key,value 为任意值,形成散列表 A
2、遍历第二个字符串数组,将字符串作为 key,去散列表 A 中查找,找到了则表明是相同的,用新数组 R 存起来,直到遍历完毕后,数组 R 内就是这两个字符串数组相同的字符串