17、跳表
思考:为什么 Redis 一定要用跳表来实现有序集合?
主要内容
跳表:为了实现“二分查找”而改造的链表结构称为“跳表”,给链表加上多级索引
普通链表,即使是顺序存储了数据,但是查找的话还是只能从头到尾,时间为 O(n)
如何加上多级索引呢?
比如原始的链表如下:如果要找值为 16 的,则需要依次遍历,第 10 次时找到了。共遍历了 10 个节点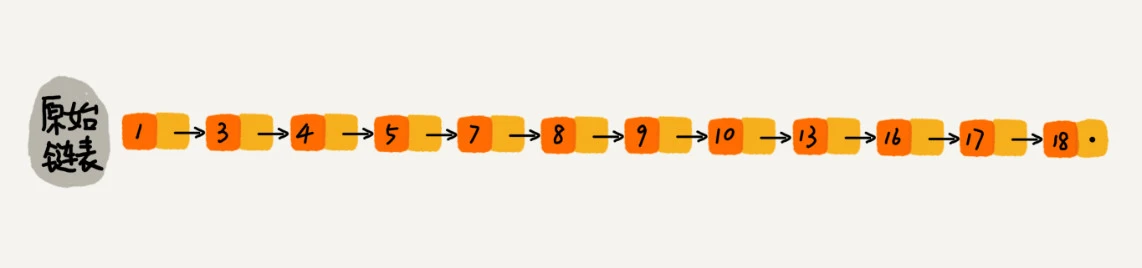
如果加上一级索引:基于原始链表,每间隔两个将其值作为索引,索引如下: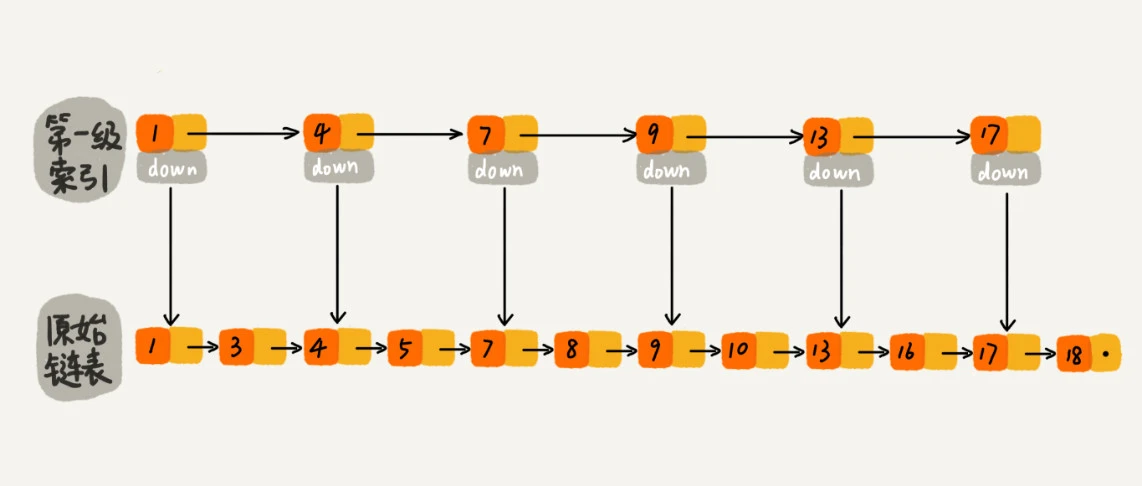
再次找 16,则先在一级索引遍历,遍历到值 13 后,发现后面值为 17,则通过 13 的 down 指针去原始链表找,发现 13 后面就是 16,则找到了。共遍历了 7 个节点
如果再加上一级索引:基于一级索引链表,每间隔两个将其值作为索引,索引如下: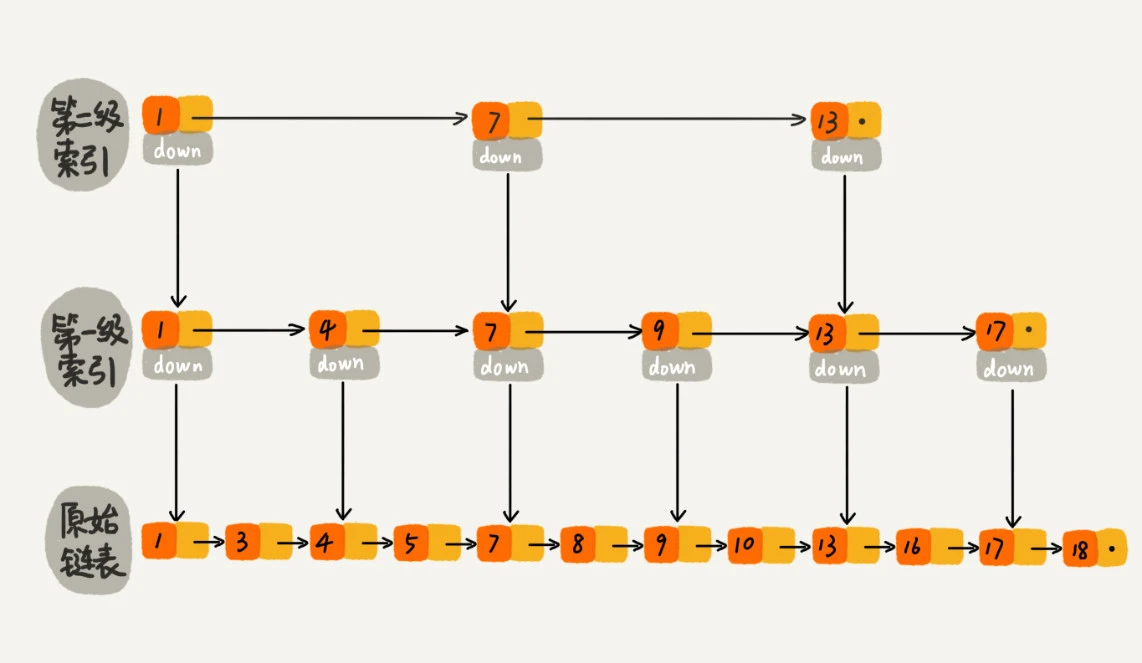
再次找 16,则先在二级索引遍历,遍历到值 13 后,发现后面没了,则通过 13 的 down 指针去一级索引链表找,发现 13 后面就是 17,则再通过 13 的 down 指针去原始链表找,,发现 13 后面就是 16,则找到了。共遍历了 6 个节点
总结:可以发现增加索引后,查找效率更高了,若数据量更大,效率提升更明显。
比如:64 个结点的链表,找值为 62 的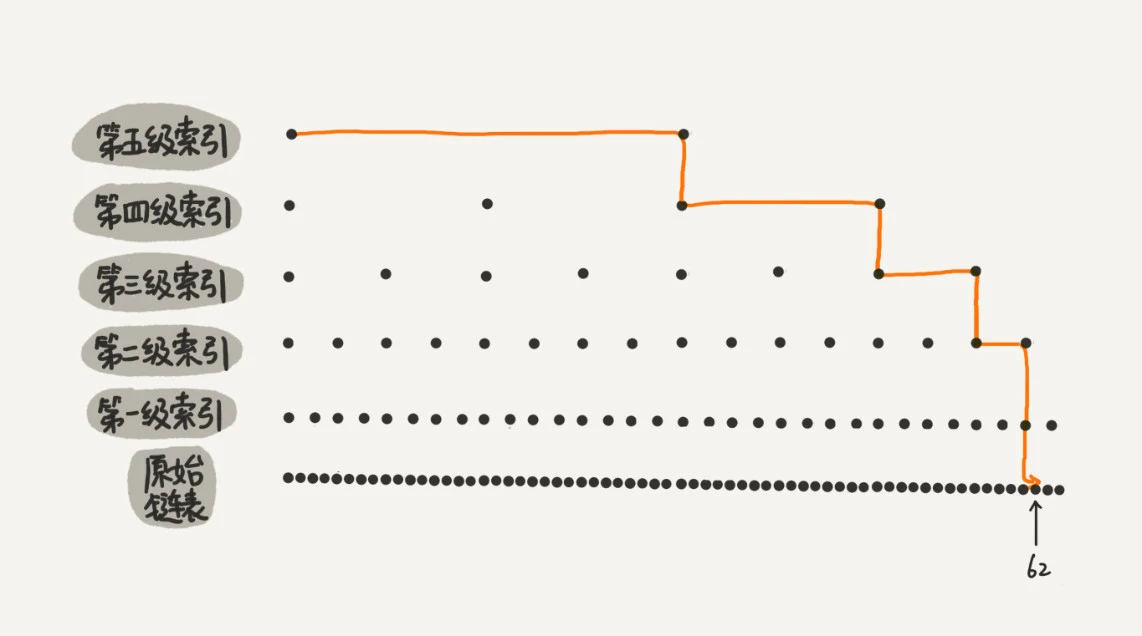
原始链表找,需要遍历 62 个节点,加了 5 层索引后,只需要遍历 11 个节点。
跳表:是链表加多级索引的结构
复杂度分析
跳表的时间复杂度为 O(logn),跟二分查找的一样,所以变相的实现了链表的二分查找~
但代价是消耗额外的内存空间存储索引,空间换时间~
所需的空间复杂度为 O(n+n/2+n/4+…+2=n-2),去掉常量则为 O(n)
但可以更改索引创建策略,比如改成每隔 3 个建索引,则变为 O(n/3+n/9+n/27+…+9+3+1=n/2),去掉常量还是为 O(n),但比每隔 2 个的,减少了一半的索引存储空间。
跳表支持动态插入与删除
跳表的插入与删除时间复杂度为 O(logn),原因如下:
链表的插入只更改指针指向,所以插入的时间复杂度为 O(1)
但普通链表麻烦的是找到插入点,时间复杂度为 O(n),最终整体时间复杂度为 O(n)而跳表找到插入点的时间复杂度为 O(logn),最终整体时间复杂度为 O(logn),比普通链表高效多了(查找带来的高效)
删除也同样如此
动态更新索引
当往链表不停插入节点时,需要及时更新索引,否则就会出现两个索引间的节点过多的情况,退化为单链表了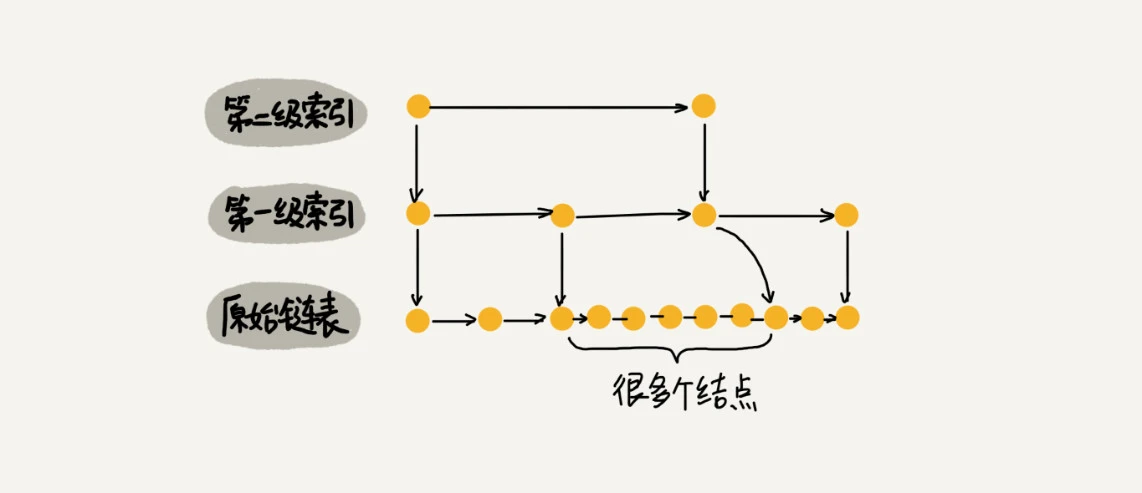
所以跳表通过随机函数来维护索引与原始链表大小的“平衡性”
比如,我插入了一个结点 6,随机函数生成了 2,则将这个节点 6 插入到 [1, 2] 级索引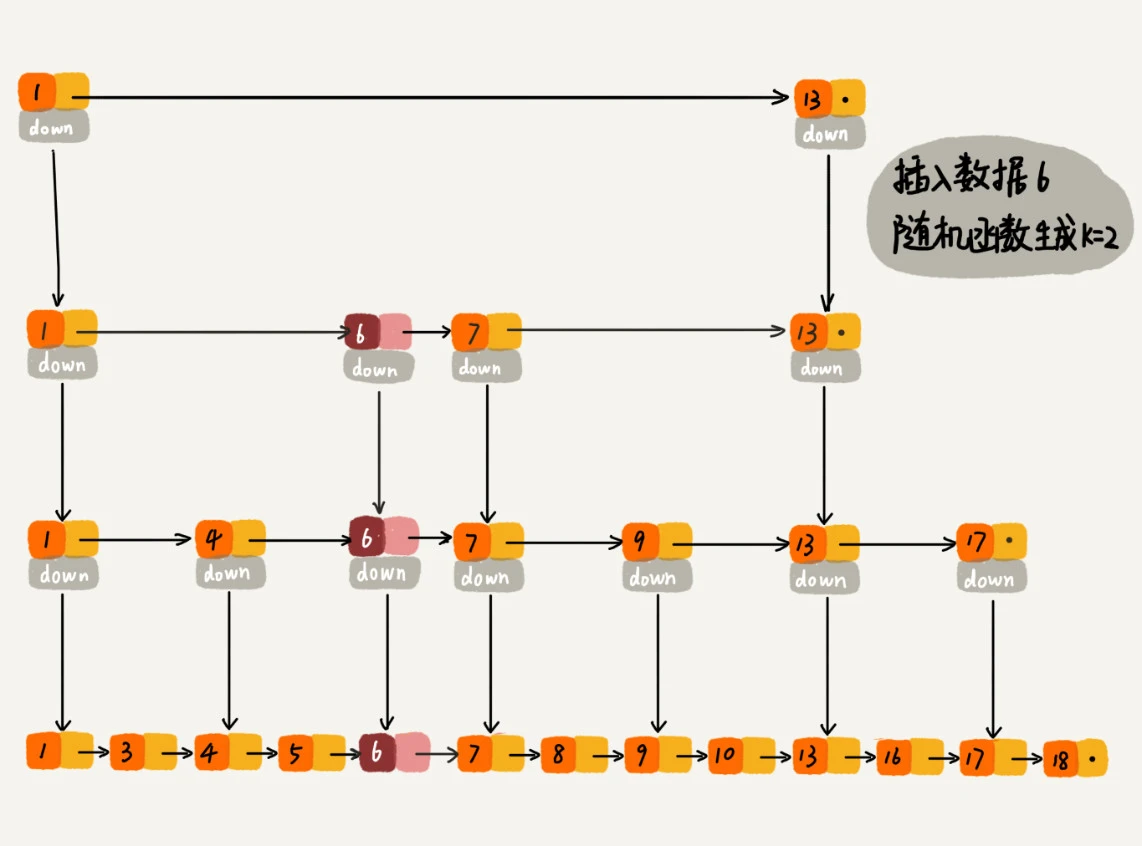
通用整理下:插入节点时,随机函数生成 K,则将该节点插入 [1, K] 级索引中
所以随机函数很重要,它那个一定程度上维持“平衡性”
解答思考
思考:为什么 Redis 一定要用跳表来实现有序集合?
解答:跳表实现更简单;索引策略更灵活;
内容总结
跳表:以空间换时间的思想,通过构建多层索引来提高效率,时间复杂度为 O(logn),类似于“二分查找”理念,支持动态插入、删除、查找等操作
新的思考
如果每三个或者五个结点提取一个结点作为上级索引,对应的在跳表中查询数据的时间复杂度是多少呢?
还是 O(logn)
推导过程自己百度吧